Das Server-Side-Tracking hat sich heute als solide Alternative zum Client-Side-Tracking für die Datensammlung und -analyse durchgesetzt. Durch die Verlagerung der Tag-Verwaltung auf den Server gewährleistet diese Methode eine höhere Datengenauigkeit, einen besseren Schutz der Privatsphäre der Nutzer und eine verbesserte Web-Performance. In diesem Artikel untersuchen wir im Detail, was Server-Side-Tracking ist, welche Vorteile es bietet und wie es in eine Data-Tracking-Strategie implementiert werden kann.
Was ist Server-Side-Tracking?
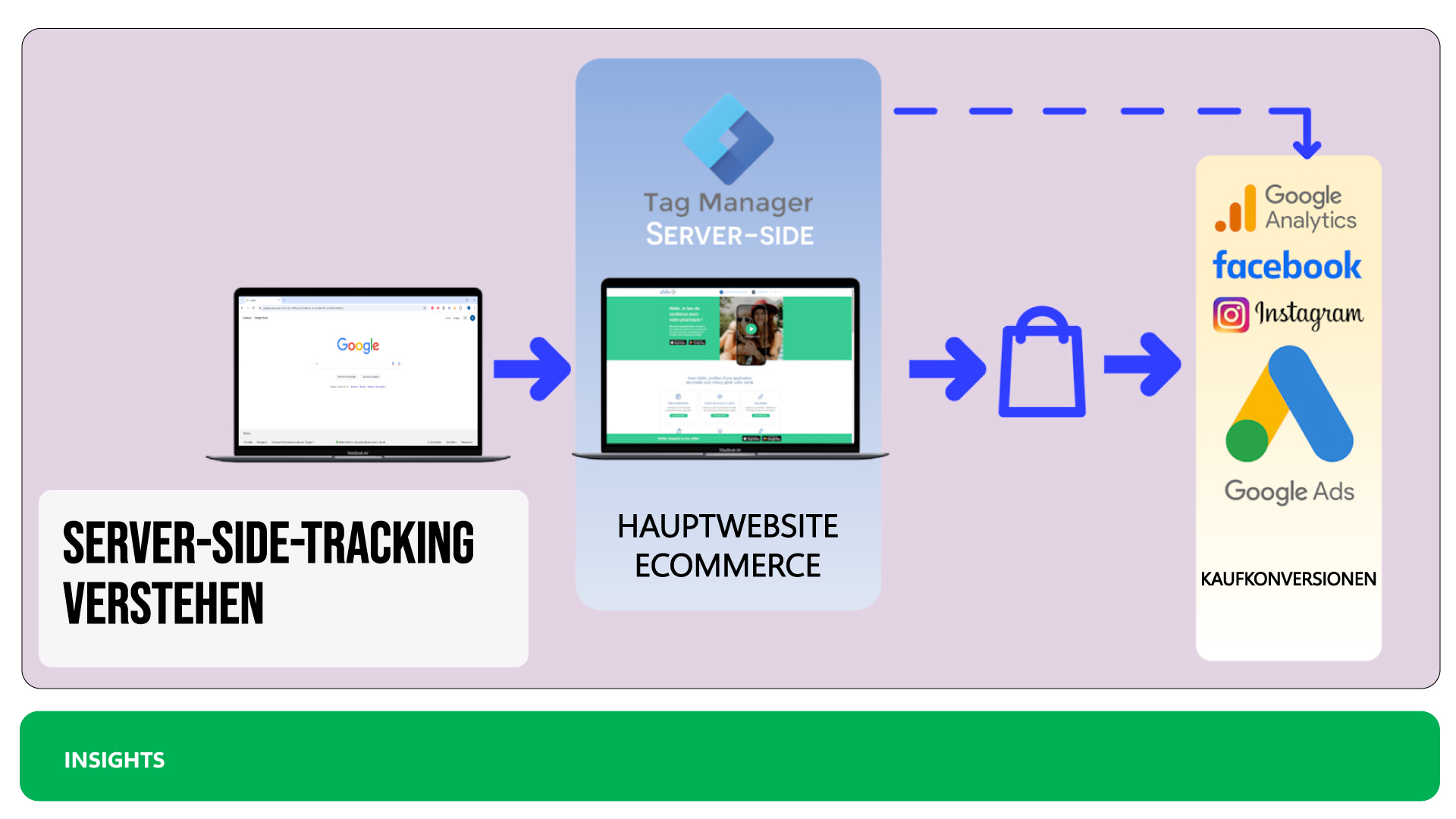
Im Gegensatz zum Client-Side-Tracking, bei dem die Nutzerverfolgung direkt im Browser über JavaScript-Tags abgewickelt wird, wird beim Server-Side-Tracking die Datensammlung zentralisiert, indem die Daten direkt auf einem Remote-Server verarbeitet werden. Die Informationen der Besucher werden an einen speziellen Tracking-Server gesendet, der die Daten analysiert und an Marketing- oder Analyseplattformen wie Google Ads, Facebook Ads oder Google Analytics 4 usw. weiterleitet.
Kurz gesagt: Anstatt die Informationen des Nutzers von seinem Browser an die verschiedenen Tracking-Tools weiterzuleiten, laufen die Daten zunächst über einen zentralen Server. Dieses System ermöglicht eine feinere Kontrolle und eine bessere Vertraulichkeit der Daten.
Quelle : https://developers.google.com/tag-platform/tag-manager/server-side/intro?hl=fr
Warum sollte man sich für ein Server-Side-Tracking entscheiden?
In einer sich ständig verändernden digitalen Landschaft, in der der Datenschutz zu einer absoluten Priorität geworden ist, bietet sich das Server-Side-Tracking als ideale Lösung für Unternehmen an, die ihre Daten kontrollieren und ihre Marketingleistung optimieren möchten. Hier sind die wichtigsten Vorteile:

- Höhere Datengenauigkeit: Im Gegensatz zum Client-Side-Tracking, das anfällig für Adblocker und Browserbeschränkungen ist, liefert das Server-Side-Tracking zuverlässigere und vollständigere Daten.
- Blockierung von Cookies von Drittanbietern: Browser wie Safari und Firefox blockieren standardmäßig Cookies von Drittanbietern, und auch Google plant, diesen Weg zu gehen. Mit Server-Side-Tracking kann diese Einschränkung umgangen werden, indem die Daten über sichere Server übertragen werden.

- Bessere Datenschutzkontrolle und Einhaltung gesetzlicher Vorschriften: Das DSG in der Schweiz, die DSGVO in Europa und der CCPA in Kalifornien enthalten strenge Regeln für die Erhebung und Verarbeitung personenbezogener Daten. Dieses Modell schränkt die Verwendung von Cookies auf dem Browser des Nutzers ein.
- Leistungsoptimierung: Die serverseitige Datenverarbeitung entlastet den Seitenaufbau und verbessert die Nutzererfahrung, indem weniger Anfragen direkt im Browser ausgeführt werden. Die Seiten werden schneller geladen, was die Absprungrate verringert und die SEO verbessert.
Wie richte ich das Server-Side-Tracking ein?
Um ein serverseitiges Tracking einzurichten, sind einige technische Schritte erforderlich. Hier ein Überblick über die wichtigsten Schritte:
- Wählen Sie ein Tag Management System (TMS): Zu den beliebtesten gehört der Google Tag Manager (GTM) Server-Side, aber es gibt auch andere Plattformen wie Segment und Tealium.
- Konfigurieren Sie den Server für den Empfang der Daten. Es ist möglich, Cloud-Lösungen wie Google Cloud Platform, AWS oder Microsoft Azure zu verwenden, um den Server für die Datenerfassung zu hosten.
- Integrieren Sie Tags von Marketing(Meta, TikTok, LinkedIn, DV360, Google Ads usw.) und Analyseplattformen und leiten Sie vorhandene Tags von Client-Side auf Server-Side um.
- Ereignisse sammeln und Daten weiterleiten: Das serverseitige Tracking funktioniert, indem es die Nutzeranfragen auf dem Server der Website abfängt, bevor sie an die Plattformen gesendet werden. Wenn ein Nutzer beispielsweise eine Aktion auf einer Website ausführt (Klick, Scrollen usw.), wird diese Aktion zunächst vom Server aufgezeichnet, der die Informationen dann an die Plattform weiterleitet. Dieses Modell stellt sicher, dass die Daten vor der Übertragung gefiltert und bereinigt werden, wodurch das Risiko von Fehlern oder Duplikaten verringert wird.
- Testen Sie, um sicherzustellen, dass die Daten richtig übertragen werden und verwertbar sind. Bevor Sie das Tracking produktiv einsetzen, müssen Sie die Konfiguration unbedingt auf verschiedenen Browsern und Geräten testen, um sicherzustellen, dass die Daten zuverlässig und konform gesammelt werden.
- Überwachung und Optimierung: Ist das serverseitige Tracking einmal eingerichtet, muss es kontinuierlich überwacht und optimiert werden. Es empfiehlt sich, die Leistung der Server zu überwachen und die Erfassungsregeln zu aktualisieren, um sie an regulatorische und technologische Entwicklungen anzupassen.
Was sind die Herausforderungen des Server-Side-Trackings?
Obwohl es vielversprechend ist, bringt das Server-Side-Tracking einige Herausforderungen mit sich:
- Komplexität der Implementierung
Die Einrichtung eines Server-Side-Trackings erfordert hohe technische Fähigkeiten und eine leistungsfähige Serverinfrastruktur. - Coût
Contrairement au tracking client-side, le server-side implique des coûts supplémentaires en termes d’hébergement. Le choix d’un modèle adapté à son budget et à ses objectifs est donc essentiel. - Auswirkungen auf die Einholung von Einwilligungen
Server-Side-Plattformen müssen so konfiguriert werden, dass sie die Einwilligungspräferenzen der Nutzer respektieren, was die Verwaltung der Consent Management Platform (CMP) komplexer machen kann. Unternehmen sollten sicherstellen, dass die Server-side-Konfiguration die Zustimmungspräferenzen der Nutzer respektiert.
Kontextualisierung mit den aktuellen Herausforderungen
Die „cookieless future“ und das serverseitige Tracking für Werbetreibende.
Die Entwicklung hin zu einer Zukunft ohne Cookies von Drittanbietern, die durch verschärfte Datenschutzbestimmungen und Browserinitiativen zur Einschränkung ihrer Verwendung beschleunigt wird, verändert das digitale Marketing grundlegend. Dieser Übergang reduziert die traditionellen Tracking- und Targeting-Möglichkeiten, was sich direkt auf die Werbetreibenden auswirkt.
In diesem Zusammenhang taucht das serverseitige Tracking als eine relevante Lösung für Werbetreibende auf. Durch die Verlagerung der Tracking-Logik auf den Server umgeht diese Methode die Einschränkungen, die mit Cookies von Drittanbietern verbunden sind, und sorgt für Kontinuität bei der Datensammlung und -analyse. Key Performance Indicators (KPIs) wie die Konversionsrate, die Kosten pro Akquisition (CPA) und die Investitionsrendite (ROI) gewinnen an Stabilität, da die über den Server gesammelten Daten weniger anfällig für Verluste durch Werbeblocker oder Datenschutzrichtlinien sind. So können Werbetreibende in ihren Marketingkampagnen ein hohes Maß an Personalisierung und Effizienz aufrechterhalten und gleichzeitig neue Datenschutzanforderungen erfüllen.
Integration von Server-Side-Tracking und Privacy Sandbox: Der Schlüssel zum Aufschließen einer datenschutzfreundlicheren Werbezukunft.
Googles Privacy Sandbox ist eine Reihe von APIs und Technologien, die es Webseitenbetreibern ermöglichen sollen, weiterhin personalisierte Werbeerlebnisse zu bieten und dabei die Privatsphäre der Nutzer zu schützen. Das Server-Side-Tracking passt perfekt zu dieser Initiative, da es eine Alternative zu Drittanbieter-Cookies bietet, die mit den neuen Standards von Google kompatibel ist.
Im Rahmen der Privacy Sandbox kann das Server-side-Tracking zur Implementierung von Lösungen wie der Topics API genutzt werden. Diese weist jedem Nutzer Themen von Interesse zu, die auf seinem jüngsten Browserverlauf basieren, ohne jedoch persönlich identifizierbare Informationen preiszugeben. Diese Themen, die lokal auf dem Gerät des Nutzers berechnet werden, werden dann mit den Werbetreibenden geteilt, um relevante Werbung zu liefern.
Ergänzend zur Topics API bieten Lösungen wie Protected Audience API und Attribution Reporting erweiterte Funktionen, um die Wirksamkeit von Werbekampagnen zu messen und Konversionen zuzuordnen. Protected Audience API ermöglicht eine privatere Auswahl und Schaltung von Anzeigen, während Attribution Reporting genauere Daten über die Customer Journey liefert.
Durch die Kombination von Server-Side-Tracking und Privacy Sandbox können Unternehmen so weiterhin zielgerichtete Werbeerlebnisse bieten und gleichzeitig die Wahlmöglichkeiten der Nutzer respektieren und neue Datenschutzbestimmungen einhalten.
Quelle : https://developers.google.com/privacy-sandbox/private-advertising/topics?hl=fr
Abschließend: Welche Zukunft hat das Server-Side-Tracking?
Server-Side-Tracking ist ein großer Fortschritt für Unternehmen, die ihre Datensammlung optimieren und gleichzeitig Leistungs- und Datenschutzauflagen erfüllen wollen. Da die Browser ihre Beschränkungen für Drittanbieter-Cookies verschärfen und die Verbraucher sensibler auf den Schutz ihrer Daten reagieren, könnte sich das Server-Side-Tracking als DER Standard für jede ehrgeizige und nachhaltige Datenstrategie durchsetzen. Unternehmen, die diesen Ansatz verfolgen, werden sich einen Wettbewerbsvorteil verschaffen, indem sie ihren Nutzern ein datenschutzfreundliches Erlebnis bieten.
Für einen erfolgreichen Übergang empfiehlt es sich, mit Experten für Tracking und Compliance-Management zusammenzuarbeiten, wie den GTM- und GDPR/LPD-Spezialisten bei Mediamix, um eine optimale Einführung zu gewährleisten. Kontaktieren Sie uns, um von unserem Fachwissen zu profitieren.
FAQs zum Server-Side-Tracking
Ist Server-Side-Tracking für alle Unternehmen geeignet?
Server-Side-Tracking kann für Unternehmen jeder Größe von Vorteil sein, ist aber vor allem für Unternehmen mit fortgeschrittenen Anforderungen an die Datenverfolgung (E-Commerce-Website) zu empfehlen. Für kleinere Unternehmen oder Unternehmen mit einem begrenzten Budget können hingegen Client-Side-Lösungen ausreichend sein, sofern sie sich an die bewährten Verfahren zum Datenschutz und zur Datensicherheit halten.
Welche Kosten sind mit serverseitigem Tracking verbunden?
Die Einrichtung einer Server-Side-Infrastruktur kann kostspielig sein, aber die Investitionsrendite ist für datengetriebene Unternehmen oft substanziell.
Wenn Sie sich für Plattformen wie Google Tag Manager Server-Side entscheiden, können einige Funktionen kostenlos sein, andere (wie das Hosting) werden jedoch nutzungsabhängig abgerechnet.
Kann man neben dem Server-Side-Tracking weiterhin ein Client-Side-TMS verwenden?
Es ist durchaus möglich, während einer Übergangszeit beide parallel zu nutzen. So können die Ergebnisse verglichen und sichergestellt werden, dass die Umstellung auf Server-side reibungslos verläuft. Langfristig ist es jedoch empfehlenswert, einen Server-Side-Ansatz zu bevorzugen, um alle Vorteile dieser Technologie nutzen zu können.
Was ist FLoC (Federated Learning of Cohorts)?
FLoC ist eine von Google entwickelte Technologie, um gezielte Werbung ohne die Verwendung von Cookies von Drittanbietern anzubieten. Sie gruppiert Nutzer nach ihren Interessen in „Kohorten“ (Gruppen) und ermöglicht so die gezielte Ansprache von Zielgruppen, ohne die einzelnen Personen zu identifizieren. Jeder Nutzer wird so in eine Kohorte von Tausenden anderer Personen mit ähnlichem Online-Verhalten aufgenommen. 2021 stellte Google die Entwicklung von FLoC aufgrund von Bedenken hinsichtlich des Datenschutzes und der Effektivität ein. Die Technologie wurde durch die Topics API ersetzt, die Nutzern auf der Grundlage ihres jüngsten Browserverlaufs Themen von Interesse zuweist, ohne dabei persönlich identifizierbare Informationen preiszugeben.
Quelle : https://privacysandbox.com/intl/en_us/proposals/floc/
Was ist die Topics API?
Diese API ist Teil der Privacy Sandbox von Google und ersetzt FLoC. Sie ordnet jeden Nutzer einer Reihe von Themen von allgemeinem Interesse (z. B. „Technologie“ oder „Reisen“) zu, die auf seinem letzten Surfverhalten basieren. Diese Themen werden dann mit Werbeplattformen geteilt, um relevante Werbung anzubieten, ohne spezifische persönliche Daten zu übermitteln.
Quelle : privacysandbox.com
Was ist die Protected Audience API?
Die Protected Audience API , früher bekannt als FLEDGE, ist ein Vorschlag von Google im Rahmen der Privacy Sandbox Initiative. Sie soll Retargeting-Werbung und die Erstellung von Custom Audiences ohne die Verwendung von Drittanbieter-Cookies ermöglichen und gleichzeitig die Privatsphäre der Nutzer schützen.
Funktionsweise der Protected Audience API :
- Interessengruppen: Wenn ein Nutzer eine Website besucht, kann die Website den Browser bitten, den Nutzer zu einer bestimmten Interessengruppe hinzuzufügen, die auf den Interaktionen des Nutzers mit der Website basiert. Diese Informationen werden lokal im Browser gespeichert.
- Lokale Auktionen: Wenn ein Nutzer eine Website mit Werbeflächen besucht, führt der Browser eine lokale Auktion durch und verwendet dabei die Daten der Interessengruppen, denen der Nutzer angehört. Diese Auktion bestimmt, welche Werbung angezeigt wird, ohne dass die Daten des Nutzers an Dritte weitergegeben werden.
- Anzeigenschaltung: Die ausgewählte Werbung wird dem Nutzer über einen sicheren Rahmen angezeigt, wodurch sichergestellt wird, dass die Daten des Nutzers nicht offengelegt werden.
Quelle : https://developers.google.com/privacy-sandbox/private-advertising/protected-audience?hl=fr
Was ist das Attribution Reporting API?
Das Attribution Reporting API ist eine Initiative von Google im Rahmen des Privacy Sandbox-Projekts zur Messung der Effektivität von Online-Werbung unter Wahrung der Privatsphäre der Nutzer. Mithilfe dieser API können Werbetreibende und Werbeplattformen feststellen, ob eine Interaktion mit einer Anzeige (wie ein Klick oder eine Impression) zu einer Konversion wie einem Kauf oder einer Registrierung führt, ohne dabei auf Cookies von Drittanbietern zurückgreifen zu müssen.
Quelle : https://developers.google.com/privacy-sandbox/private-advertising/attribution-reporting
Funktionsweise der Attribution Reporting API :
- Aufzeichnung von Quellen: Wenn ein Nutzer auf einer Publisher-Website mit einer Anzeige interagiert, wird diese Interaktion als „Attributionsquelle“ aufgezeichnet.
- Aufzeichnung von Auslösern: Wenn der Nutzer zu einem späteren Zeitpunkt eine Conversion-Aktion auf der Website des Werbetreibenden durchführt, wird diese Aktion als „Attributionsauslöser“ aufgezeichnet.
- Attributionsberichte: Die API verknüpft Quellen und Auslöser, um Berichte zu erstellen, die die Wirksamkeit von Werbekampagnen anzeigen, wobei die geteilten Informationen zum Schutz der Privatsphäre der Nutzer eingeschränkt werden.